

Practical Ontologies & How to Build Them - Part 1
Part 1: Ontology concepts and data modeling


This is the first installment of a four-part series exploring the use of ontologies in data modeling and how to build practical ontologies that are useful to both describe and drive a business’s critical operations.
To begin, we’ll consider ontologies from first principles and discuss their relationship to existing concepts in database design. In the second part of the series, we’ll outline the process of creating an ontology in Palantir Foundry and discuss some useful methods for arriving at a practical solution quickly. The third part of the series will explore the use of time series data in the Foundry ontology and outline the key differences between objects, events and time dependent properties. The final part in the series will look at “actions” in the Foundry ontology and their importance in operationalizing an organization’s data.
Ontological Thinking and Database Design
Definitionally, an ontology is simply a set of concepts or categories within a specific domain and the relationships between them. Ontology as a field of academic study is a branch of philosophy concerned with what “is,” with the etymology of the word originating from the Greek word “ontos”, meaning “being”. In data analytics, the concept of ontologies has been familiar to database architects since the earliest efforts to design more efficient, normalized databases going back to the 1970s.
One example of ontological thinking in database design lies in the exercise of developing databases adhering to the third normal form (or 3NF). The concept of “normal forms” refers to the application of increasingly strict requirements on the tables within a database that, when adhered to, break down the data into smaller (if more numerous), conceptually self-contained tables that are easier to reason about and work with.
Beginning with the first normal form (1NF), a database meeting the requirements of 1NF implies that all tables have a primary key, each row in each table is unique and column values are atomic (only one value per cell).
An example of a table NOT in 1NF is this table describing the courses several university students are taking:
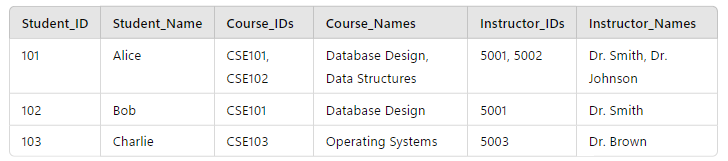
In the table, each row is unique but the properties related to the courses have been grouped together into arrays, which breaks the “atomic” requirement. The same table in 1NF form would be:
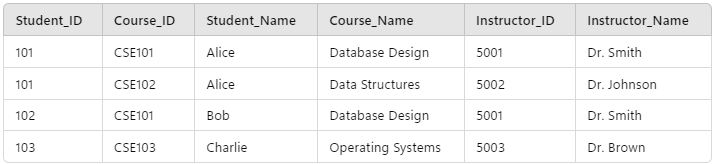
Student_ID and Course_ID together) and the arrays have been broken out into individual rows.What’s interesting to note is that in the process of ensuring the table is in 1NF, we’ve inadvertently made an ontological statement: the concept we’re representing is an “Enrollment” (even if we haven’t explicitly named it as such yet), i.e. each combination of a student and course.
At this point the table is still not in 2NF, or the second normal form. The primary difference between 1NF and 2NF is that in a 2NF structure, each column in each table must depend on all components of the table’s unique identifier (or “primary key”), should the primary key be a composite of two or more other columns. For example, in the 1NF table above the columns Student_Name and Course_Name depend on Student_ID and Course_ID respectively (the two columns which make up the composite primary key), but do not depend on each other. A simpler way of saying this is that the student’s name is a property of the student, not a property of the course or the enrollment.
If the student associated with the enrollment changed (i.e. the Student_ID for the enrollment was modified), the Student_Name column would also potentially update (assuming the new student had a different name), but the Course_Name would be unaffected. Conversely, the Course_Name, Instructor_ID and Instructor_Name all depend on the Course_ID but not the Student_ID.
In this 1NF structure, should the student’s name change, each corresponding row in the Enrollment table would need to be updated, and this type of change becomes very inefficient as the table grows larger.
An example in 2NF would therefore be:
Students:

Courses:

Enrollments:

Note that we haven’t achieved the third normal form (3NF) yet, as we still have a transitive dependency in our Courses table. A transitive dependency occurs when a non-key column depends on another non-key column. In this case, Instructor_Name depends on Instructor_ID, separately to depending on the primary key of the table, Course_ID. This can occur when there exists a foreign key in the table which links to another conceptual entity (an “instructor” in this case) as well as one or more properties of that other entity (for example, the instructor’s name). Therefore, we still have properties in one of our tables that do not belong to the conceptual entity the table is describing (do not depend solely on the primary key of the table), and we need to eliminate this dependency if we want to reach 3NF.
To achieve 3NF, we will now break out the transitive dependency of the Instructor_Name into a new table capturing the properties of instructors and modify the Courses table to remove the Instructor_Name column.
Instructors

Courses (Updated)

In the process of building a 3NF representation of our original dataset, we can say that we’ve designed an ontological representation of the underlying information. We have decided that the underlying conceptual model describing the data involves “Students”, “Courses”, “Instructors” and “Enrollments”, as well as the relationships between them.
The key difference between thinking ontologically and thinking in terms of normal forms is that generally an ontology is focused on the real-world entities and relationships the data is representing, whereas normal form normalization is primarily concerned with organizing the data to reduce redundancy and minimize the chance of technical issues or anomalies when updating the data. There is, however, significant overlap in the two approaches.
As we continue with this series on ontologies and data modeling, we’ll leave the concept of normal forms behind and focus our attention on how to map an organization’s data to an ontology that accurately and usefully describes core business operations.
Ontology as a Statement: What Matters to Your Business?
Any time you design or update an ontology, you are making statements about what objects, events, relationships and properties your organization or business unit cares about and what information it needs to operate. This process presents an opportunity to simplify and clarify your data landscape by making thoughtful, opinionated design choices. Here are some useful questions to ask yourself as you go through this process:
When adding a new object to your ontology, or updating an existing one:
Does this new object type need to exist? Does it improve the visibility of our conceptual landscape the ontology is describing, or might it convolute it in some way?
Is the object at the right level of abstraction? Does it provide us with a sensible place to store all the properties we will want to work with in the future, without needing transitive dependencies? For example “Vehicles” vs “Cars”, “Motorbikes” and “Busses” (more on this in Part 2 of this series).
What should the object type be called? Is it named well to clearly and intuitively describe the concept it represents?
When adding a new property to an existing object:
Does this new property truly belong to the object I’m attaching it to? Or does it duplicate another property on an object that already exists?
What should the property be named? Is the property name sufficiently descriptive so that it is intuitive to understand and work with?
What data type should this property have? Does the type selection appropriately account for its context and purpose? E.g. dates vs timestamps.
When adding or updating relationships (or “links”) between objects in the ontology:
What is the type of this relationship?
One to one? One object of the first type relates directly to exactly one object of the second type. E.g. a School’s current Principal
One to many? One object of the first type relates to potentially many objects of the second type. E.g. a Vehicle’s recent Services
Many to many? One object of the first type relates to potentially many objects of the second type and one object of the second type relates to potentially many of the first type. E.g. a Course’s supporting Teaching Assistants (each assistant may help with multiple courses, and each course may have multiple assistants helping)
What are the existing relationships between the objects in our ontology and are we duplicating an existing link?
How should the relationship be named so as to make it as easy to understand and use as possible?
In what ways would users expect to be able to traverse the ontology and have we provided a sufficient set of links to enable that traversal?
Follow us and make sure to check out the next part of this series, where we’ll take a look at Palantir Foundry’s ontology concepts, how to construct an ontology, and how to best take your organization’s data landscape into account when doing so.

With 110+ years of combined experience, Fourth Age is a leading consultancy focused on delivering value with Palantir Foundry and AIP. We provide a full range of services to ensure our partners can maximize the value of their strategic software investments, including strategic consulting, end-to-end use case delivery and long-term enablement. If you’d like to learn more about how we can help you unlock the potential within your organization’s data, reach out to us via our website.