

Practical Ontologies & How to Build Them - Part 2
Part 2: Building operational ontologies in Palantir Foundry


This is the second in a four-part series on how we can apply ontological thinking to help us operationalize data using Palantir Foundry. In part one, we introduced the concept of an ontology and related database design principles. In this installment we’ll explore the use of ontologies in Palantir Foundry platform and some key considerations to bear in mind when mapping your organization’s data to ontological concepts.
The Palantir Foundry Ontology
Large organizations inevitably have complex data landscapes. This is simply the result of having many disparate processes creating information (i.e. data) and that information often being siloed into different databases from the start. An example could be a heavy machinery workshop producing and storing data about the happenings on the workshop floor, while simultaneously yet separately storing data about the financial transactions of the organization in an entirely different system. The financial transactions may refer to aspects of the workshop’s operation (such as labour expenses or consumable prices) but are not connected at a technical level.
Palantir Foundry is a SaaS platform that helps organizations operationalize their data through the use of ontologies. Foundry’s ontology is a semantic layer placed over an organization’s data to formalize the concepts (or object types), connections (link types) and operational processes (actions) that describe the organization’s operations. Structuring the organization’s data this way dramatically simplifies the data landscape in order to enable humans to interact with business-critical information in a way that matches their intuitive understanding of the world. Humans, of course, have a much easier time thinking in concepts and relationships than in terms of rows and columns optimized to be read by computers.
The process of defining an organization’s ontology is very similar to the process of converting a denormalized database into 3NF (as detailed in part one of this series). When thinking from an ontological perspective however, the typical questions a database architect might ask themselves such as “do I have a composite primary key?” or “do I have any transitive dependencies?” can be converted to less esoteric ones. For example, one might ask themselves these high-level questions when first developing an ontology:
What are the primary nouns (or concepts) used to describe the operations of the business? These form the object types in your ontology. (For example: “Students”, “Courses”, Enrollments”, “Instructors”, “Lectures”, “Attendance Records”, “Exams”, “Exam Results”)
What properties belong to each noun (or concept/object type)?
How do these nouns relate to each other? These relationships lead to the development of links between your ontology objects.
What are the primary verbs used to describe actions that generate data within the business? (For example: “Enroll”, “Attend”, “Drop Out”, “Teach Class”, “Take Exam”, “Mark Exam”)
What are the verbs used to describe actions that update existing data within the business? (For example: “Change Grade”, “Update Student Name”)
What real-world events would trigger each verb (especially “update” verbs) to occur?
Who performs these actions?
What information do they typically need to know to inform their action or decision?
What data sources exist within the organization that store the properties of its nouns or the results of its verbs? (For example, a school might have a database of students updated when a new student enrolls, as well as a database of exam results which are updated when a student takes an exam.)
What processes within the organization could benefit from improved access to information and what ontological objects, relationships and actions would be required to describe and carry out those processes? (For example, a school may aim to assess whether a student likely needs additional support based on historical exam results, their attendance rates and the particular courses they’re enrolled in.)
The last point is critical when devising a practical ontology that enables the kind of operational improvement typically targeted using Foundry. The ontology needs to be detailed enough to capture the information required for operations, while remaining simple enough that end-users can easily understand and use it to meet their needs. There’s also a third consideration which is specific to Foundry: what tooling does Foundry provide for defining and managing an organization’s ontology, and what design patterns and best practices help us leverage those tools?
Work with the data you have
Assuming you have considered your organization’s ontological landscape, its primary business operations and defined the needs of the business in terms of process improvement, the next step is to consider the data available that could describe this landscape.
This is where ontology design becomes both an art and science, as the data itself may constrain the space of possible ontological objects one could create. For example, using our educational facility and the goal of identifying students who may need additional support such as tutoring or mentorship, we may want to utilize attendance records on a lecture-by-lecture basis to determine whether a student’s attendance across their enrolled courses is a relevant factor. If, however, attendance records are only stored at an aggregate level, on an annual basis as a single percentage figure for each student, then the data simply wouldn’t be available for the ideal “Lecture Attendance Record” object that we might have hoped to create. In this instance we would need to adjust our ontology to account for the underlying data we’re able to utilize and create something like “Annual Attendance Record”, identified by the student and year and capturing their overall attendance percentage.
Note that “work with the data you have” does not mean “model the data as it exists today” in all cases. Similar to the process of normalizing tables to a 3NF representation, an organization’s data can be transformed and modelled as close to the real-world ontological representation of its operation as possible, adhering only as much as is necessary to its underlying data structure. That is, while the underlying data landscape constrains your ontology design, it should not define it more than is necessary.
To take another example, imagine a vehicle manufacturer with the following data source available:
Recently Manufactured Vehicles with Identified Issues by Week
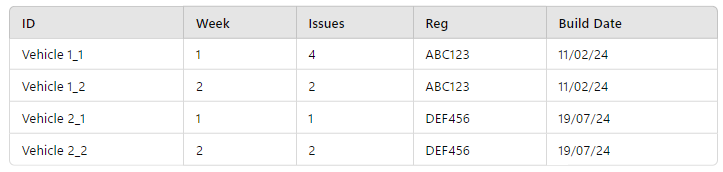
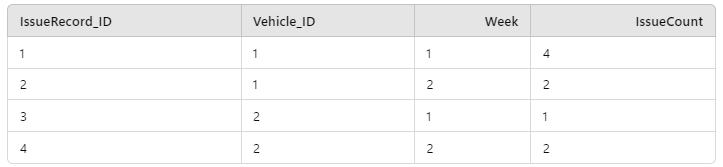
Here a specific dataset is being produced by the business, and there is nothing fundamental in Foundry to stop us using the table directly to create an ontology object per row (albeit by using a convoluted object type!). Yet it’s reasonably clear that the ontology object types we would want to create from the table would be better as “Vehicle” and “Weekly Issue Report”. We could not, however produce a “Daily Issue Report” without getting access to additional tables from the source system, as the information simply isn’t captured in the weekly summary.
Vehicles
Weekly Issue Reports
When to Split: Is the Level of Abstraction Practical?
A common problem in ontology design is the question of when to break up a single object type into constituent sub-types. For example, imagine again you’re a vehicle manufacture and you’ve created the quite sensible ontology object type for “Vehicles”. However, some new properties have been added to the Vehicle object in preparation for a new use case which examines the effect of backseats (cars) and riding posture (motorbikes) on sales. Our vehicle object now looks like this:
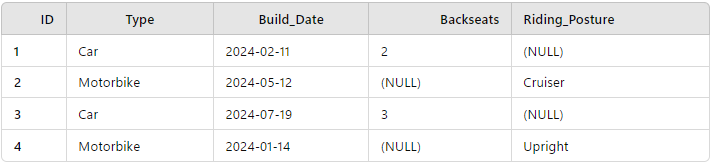
At this point we could explore two options:
Continue to use our Vehicles object as-is and hope that in future we don’t need to add too many further properties specific to one vehicle type or another
Split the object up into constituent parts that will provide us with places to store the properties local to cars or motorbikes, should more be needed in future.
Generally, the second option is better, but the decision will depend on factors like the downstream dependencies on the Vehicle object type and the effort required to refactor it into a more ideal ontological representation.
Opting for #2 would result in something like this:
Vehicles
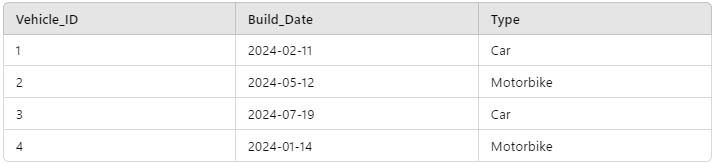
Cars

Motorbikes

We could continue to search for relevant data related to the specific Model of each car or motorbike and add that as a property of the “Cars” and “Motorbikes” objects. We could then normalize further by having “Car Models” and “Motorbike Models” objects on which the Backseats and Riding_Posture properties are finally stored, if these properties are not specific to the individual vehicles themselves and are more likely properties of the model of vehicle. Also note that in doing so we would have the option to create a single “Model” object with both properties attached, or we could separate model objects for Cars and Motorbikes - similar to the original conundrum. The only way to determine a “correct” solution is to consider both the downstream usage of the ontology and the upstream data structure, such as whether additional properties belong always to only one of the two object types.
Lastly, you may have noticed that in this instance, because we only have one property on Vehicles not already described by the Cars and Motorbikes tables (Build_Date), we have the option of having a Build_Date property on both Cars and Motorbikes and removing the Vehicles table entirely. Our decision to do so would depend on how many common properties of the Cars and Motorbikes we have and whether or not there are downstream benefits to having both sets of vehicles in the same table. For example, if we often want to do things like view the number of all vehicles built per month, retaining a single Vehicles table might be useful.
As you can see, there are generally multiple ways to model even a simple real-world situation and therefore real consideration is required in the design phase in order to build a practical and realistic representation of an organization’s operations.
Key Point: Generally, a sensible middle ground is reached by trying to minimize the number of properties relevant only to a subset of objects of a given type while simultaneously trying to maximize the abstraction of the ontological design for ease of use. As a rule of thumb, if you end up with more than one property relevant to only a subset of the objects in a type, it likely indicates the ontology needs to go one level lower in abstraction.
Property Ownership: An Ontological Thinking Heuristic
Another useful heuristic for determining the object types that should exist in an ontology is to consider the properties you’ve assigned to objects in your ontology so far and iteratively ask yourself “what object type is this actually a property of?”. If the answer is an object type other than the one the property is currently attached to, it likely indicates you need to augment the ontology with a new object type and link the old and new object types together via a relation. This can be done both during the initial ontology scoping phase (before you’ve seen any data) and also, more importantly, as you begin to back your ontology with data captured by the organisation and review properties that may have been added to objects hastily to facilitate a downstream use case.
Very often, a source system will contain tables already closely resembling ontology objects the organisation talks about, but on closer inspection the tables aren’t yet separated out into an sensible number of distinct object types. This is due to there generally being some level of deliberate denormalisation added to all databases to improve usability or efficiency. That is, databases architects will sometimes deliberately put properties from one entity onto another to forgo having to join two or more tables together to retrieve or derive that other entity’s property.
As a simple example, imagine we have a “Persons” object that contains properties of individuals such as their name and age, but also a property capturing the number of bedrooms their primary residence has. This could be considered at first glance to be a property of each person, but really is a property of their home with a relationship between each individual and the home they own providing the link.
Note that any time you find yourself describing a property in terms of an object other than the one the property is attached to (“the number of bedrooms their primary residence has”) it’s a good indication that the property does not belong to the original object.

This would be better ontologically modelled as:
Persons

Homes

Whether or when to deliberately denormalize an ontology (that is, deliberately add properties from one object onto another) is a tricky question. Although we want to apply sound ontological modelling to build the most useful data asset possible in Foundry, the reality is that some level of denormalization is quite frequent in order to make the ontology easier to use (for instance, by reducing the number of links a user needs to traverse to retrieve the information they’re looking for).
In the example above, if we know that the number of bedrooms in a person’s house is used very often when carrying out analyses involving the Persons object, it might be a net-positive to leave it on the Person object, even if we simultaneously capture the information on a Home object. This pattern of adding redundancy to improve usability is a key consideration when developing a practical ontology but should generally be used sparingly.
As with many patterns that deviate from the “perfect” ontological representation, this should be done only as much as is strictly necessary or if it offers a significant improvement in usability. If your ontology contains too many of these redundancies, it can become unwieldy, with users not knowing where to look to find the source of truth regarding an object’s properties.
In the next part in this series, we explore the concept of time series data and how it relates to the Foundry ontology. We’ll look at the difference between events and time series and when to use each when modelling your organization’s data.

With 110+ years of combined experience, Fourth Age is a leading consultancy focused on delivering value with Palantir Foundry and AIP. We provide a full range of services to ensure our partners can maximize the value of their strategic software investments, including strategic consulting, end-to-end use case delivery and long-term enablement. If you’d like to learn more about how we can help you unlock the potential within your organization’s data, reach out to us via our website.
That's a great question and something teams working with Foundry run into very regularly.
Essentially there are a few different kinds of "reporting" in this case and how you'd use an ontological approach varies depending on what you need to do. I think about it in these buckets:
1. Your report calls for aggregate properties of objects. For example imagine you have a Vehicle object and you want to know the total km driven by that vehicle in the last 12 months. Ultimately this is an aggregation over the "journeys" the vehicle has taken and so adding it as a property to the vehicle is a denormalisation of your ontology but is ok in many cases, especially if it assists with reporting efforts.
2. Your report calls for a non-temporal aggregation over an object type. For example you might have a "Persons" object, with each person having an "eye color" property. You may want to know the total number of people that have each eye colour. These kinds of aggregations are typically handled via front-end transformations and corresponding visualisations, as opposed to changing anything in your ontology itself. You could create an object for this metric but it would be a strange ontological concept. Essentially it would be an object of "Eye Color" with properties of "number of people" and "rank".
3. Your report calls for temporal aggregations over event-like objects. This is the most common report type. For example, something like a "Monthly Sales Report", which would be an aggregation over your "Sales" object. In these cases, generally a new ontology object would be created as there may be many derived properties you want to add to your Monthly Sales Report and you may want to store the result so you can easily compare months in the future. It's totally fine to create an ontology object for this kind of report and link it back to the Sales objects themselves that went into each month. The way you'd do this is by putting the primary key of the Monthly Sales Report (probably just the month) as a foreign key on the Sales object, linking that particular sale to the Monthly Sales Report Object it contributed to (the month the sale took place in).
4. Your report calls for the aggregation of multiple objects over the same time horizon. This is a common pattern for things like KPI Reports where each object (row) represents a quarter and each property (column) captures a KPI the business wants to know. Each KPI might require multiple objects to be combined together to derive. In these cases, it's again fine to create an object in a Foundry ontology to capture the "KPI Report" even though it's quite abstract. It could be tricky to connect each month back to the specific objects that contributed to the derived KPI value and so often this isn't done and the KPI Report object stands alone. This means it's usable for visualising in Foundry's downstream tools but isn't a great example of an operational ontology object. They have their place though and while it isn't Foundry's bread and butter, there's nothing to stop you doing it!
Hopefully that helps.
Really appreciate this dive into the topic. A big question for myself and my team is how we consider an ontology from a less physical perspective and more report-focused one - e.g. with this source saying one thing and another source saying another thing (but not necessarily contradicting each other). Are there good examples of teams producing an ontology/ontologies based more on reporting? Would love to chat through entity schemas and how that'd look.